Speech recognition is a subfield of artificial intelligence that enables machines to understand voice narration by identifying spoken words and converting them into text. While audio information is clear to humans, computing machinery can’t understand its semantic structure as effortlessly. To deal with this issue, there is audio labeling — when you assign labels and transcripts to audio recordings and put them in a format for a machine learning model to understand.
Speaker identification
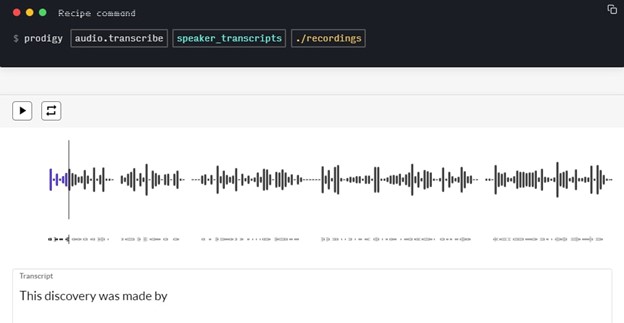
Speaker identification is a process of adding labeled regions to audio streams and identifying the start and end timestamps for different speakers. Basically, you break the input audio file into segments and assign labels to parts with speaker voices. Often, segments with music, background noise, and silence are marked too.
Audio-transcription annotation
Annotation of linguistic data in audio files is a more complex process that requires adding tags for all surrounding sounds and transcripts for speech in addition to linguistic regions. Many audio and video annotation tools allow users to combine different inputs like audio and text into a single, straightforward audio-transcription interface.
The process of audio annotation using the Prodigy tool.
Audio classification
Audio classification jobs require human annotators to listen to the audio recordings and classify them based on a series of predefined categories. The categories may describe the number or type of speakers, the intent, the spoken language or dialect, the background noise, or semantically related information.
Audio emotion annotation
Audio emotion annotation, as the name suggests, aims at identifying the speaker’s feelings such as happiness, sadness, anger, fear, and surprise, to name a few. This process is more accurate than textual sentiment analysis since audio streams provide a number of additional clues such as voice intensity, pitch, pitch jumps, or speech rate.
Audio labeling use cases
Since adding labels to audio and video files is a cornerstone of speech recognition, it finds use in
Developing voice assistants like Siri and Alexa
Transcribing speech to text
Providing the context of conversations for advanced chatbots
Measuring customer satisfaction for support calls
Designing apps for language learning and pronunciation assessment