Image and video labeling for computer vision tasks
Computer vision (CV) falls under the umbrella of artificial intelligence (AI), empowering machines with the ability to perceive visual information. Despite sounding futuristic, the concept refers to computers deriving meaningful insights from visual inputs, such as digital images, mirroring human visual perception. To achieve this, computers require image annotation – the act of assigning tags to images, and video annotation – the process of adding labels to video frames (still images extracted from video footage). Depending on the CV task at hand, workers may employ various forms of image and video annotation.
Image classification
Image classification, a fundamental computer vision (CV) task, involves assigning one label (single-label classification) or multiple labels (multi-label classification) to an image, indicating the class to which the depicted object belongs. Whether there is a cat or two cats in the picture, it will be labeled as “cat.” The same principle applies to video clip classification.

The predominant method for image annotation, bounding boxes consist of rectangular or square shapes drawn around objects to indicate their location within an image. These boxes are defined by the x and y-axis coordinates in the upper left and lower right corners of the rectangle. Bounding boxes find extensive application in object detection and classification, particularly in localization tasks. Object detection involves identifying and classifying multiple objects within an image or video frame while indicating their positions through bounding boxes. In image classification with localization, images are categorized into predefined classes based on depicted objects, and boxes are drawn around those objects. Unlike object detection, this approach is commonly employed to define the location of a single object or several objects as a single entity.

Polygon annotation
Polygon annotation employs closed polygonal chains to define the location and shape of objects. Given that non-rectangular shapes, such as a bike, are prevalent in real-world environments, polygons prove to be a more appropriate image annotation method compared to bounding boxes. With polygons, data annotators can take more lines and angles in work and change the directions of verticals to show the object’s true shape more accurately.

Bike annotated with the help of a polygon. Source: COCO dataset
Semantic segmentation
Semantic segmentation is a labeling technique utilized to assign a label to individual pixels in an image, categorizing them into a specific class based on what is depicted. Annotators draw polygons around a group of pixels they wish to tag, grouping those of the same class as a single entity and distinguishing them from the background and other objects. For instance, in the image below, all sheep are segmented as one object, while the road and grass represent the other two objects. A similar approach, instance segmentation, differentiates between multiple objects of the same class and treats them as individual instances. In the image, each sheep is segmented as an individual object in addition to the road and grass.
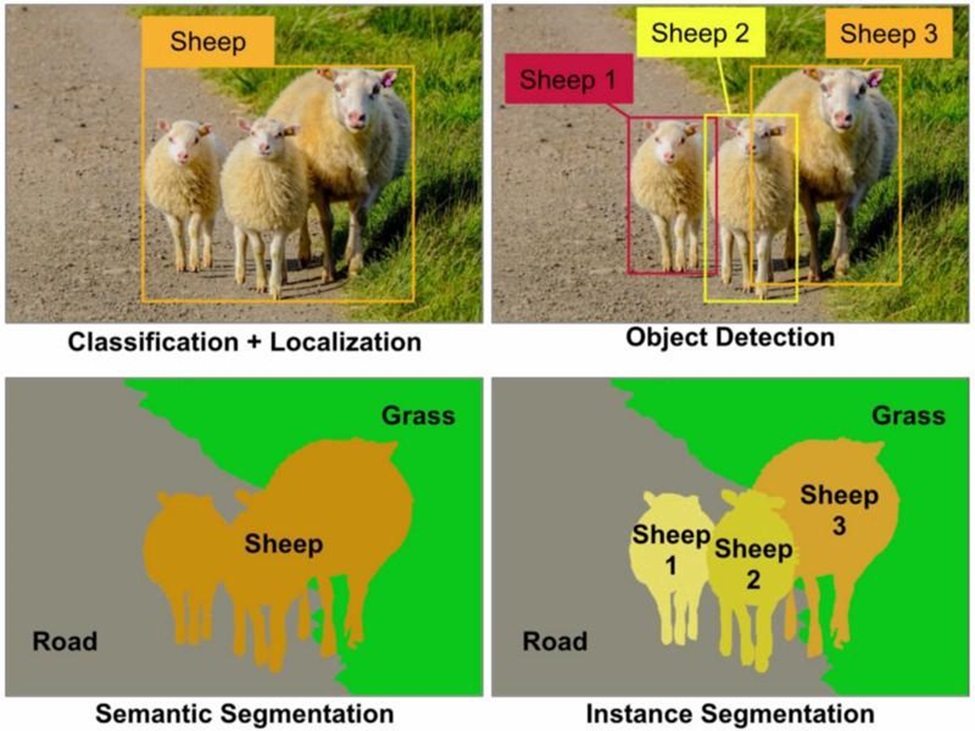
Differences between image classification, object detection, semantic segmentation, and instance segmentation. Source: Medium
3D cuboids
3D cuboids serve as three-dimensional representations of objects, capturing not only their length and width but also their depth. This allows annotators to illustrate the volume feature along with the object’s position. In cases where object edges are obscured or obstructed by other objects, annotators may approximate and define them accordingly.

The example of 3D cuboid annotation. Source: Cogito Tech
Key-point annotation
Key-point annotation entails the placement of dots throughout an image, connected by edges. The resulting output provides x and y-axis coordinates for key points, numbered in a specific order. This method proves valuable in recognizing small objects and shape variations sharing a similar structure, such as facial expressions and features, as well as human body parts and poses. Key-point annotation finds frequent application in labeling video frames.

An example of key-point annotation of a video clip. Source: Keymakr
Applications of Image and Video Labeling
The utilization of both video and image annotation spans various practical domains, showcasing its versatility. In the healthcare sector, you can annotate disease symptoms in X-rays, MRIs, and CT scans, along with microscopic images, aiding in diagnostic analysis and early detection of diseases, such as identifying cancer cells at initial stages. In logistics and transportation, labeling barcodes, QR codes, and other identification markers facilitates the tracking of goods, enhancing smart logistics processes. Within the automotive industry, segmenting vehicles, roads, buildings, pedestrians, cyclists, and other objects in images and videos proves essential for assisting autonomous cars in distinguishing these entities, thus preventing real-life collisions. In the realm of cybersecurity, annotating facial features and emotions supports AI systems in identifying individuals within images and security video footage.