Text labeling for natural language processing tasks
Natural Language Processing (NLP) is a branch of artificial intelligence focused on enabling machines to understand human language. Leveraging linguistics, statistics, and machine learning, NLP studies language structure and rules, leading to the development of intelligent systems capable of extracting meaning from text and speech. The algorithms delve into linguistic elements like semantics, syntax, pragmatics, and morphology, applying this knowledge to execute specific tasks. Below are several widely used methods for annotating text in NLP tasks.
Text classification
Text classification, also known as text categorization or text tagging, involves assigning one or more labels to entire text blocks to categorize them according to predefined categories, trends, subjects, or other criteria. Sentiment annotation is employed in sentiment analysis, which aims to determine whether a given text conveys a positive, negative, or neutral message. For instance:
“Customer service was top notch.” → Positive message “ They won’t respond to requests on the app and put me on hold for 30 mins.” → Negative message “The new design of the website is generally fine.” → Neutral message
Regarding sentiment analysis, AltexSoft has developed a machine learning-powered model proficient in scoring hotel amenities through customer reviews. We invite you to join us on this intriguing journey. In the realm of topic categorization, the challenge lies in identifying the subject conveyed in a text. During the analysis of customer reviews, annotation comes into play by adding thematic labels like Pricing or Ease of Use. Language categorization, on the other hand, revolves around detecting the language of a given text. Annotation in this context entails assigning appropriate language labels to texts based on their written language.
Entity annotation
Entity annotation involves identifying, locating, and tagging essential entities within each line of unlabeled text. Unlike text classification, entity annotation focuses on labeling individual words and phrases. Various types of entity annotation exist, including named entity recognition, keyphrase tagging, and Part-of-Speech tagging. Named entity recognition involves extracting, chunking, and identifying entities, annotating them with appropriate names. Common categories include names of people, products, organizations, locations, dates, and times, among others.

An example of how the sentence is annotated by named entities. Source: Towards Data Science
Consider that you are developing an ML model intended for stock trading based on news events. As the algorithm processes the data, it encounters a headline that appears like this:

News headline from the Financial Express resource
While humans can easily grasp the context, machines struggle to discern whether the term “Tesla” refers to a company name, a component of a Tesla vehicle, or perhaps even Nikola Tesla. Named entity annotation performs this task for machines, elucidating the correct meaning. Keyphrase or keyword extraction and tagging go beyond annotating named entities; labelers may also tag keyphrases or keywords in the text. This form of text labeling proves useful for summarizing documents/paragraphs or indexing a corpus of texts. The process entails a thorough examination of each text block to extract the most meaningful keywords. Part-of-Speech or POS tagging involves annotating all the words within a sentence based on their parts of speech. Labels encompass nouns, verbs, prepositions, adjectives, and more.
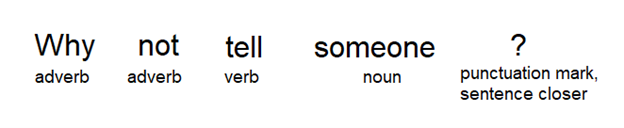
POS tagging example. Source: Towards Data Science
Utilized for discerning relationships between words within a sentence and extracting meanings, POS tagging ensures that algorithms can precisely represent similar words in various contexts, leading to more accurate results.
Entity linking
Entity linking involves labeling specific entities in text and linking them to extensive data repositories. Essentially, this occurs when tagged entities are connected to URLs containing sentences, phrases, and facts that provide additional information. This procedure is particularly crucial in cases where the text corpus contains data susceptible to multiple interpretations.
Text labeling use cases
Numerous compelling applications exist for text annotation and NLP processes, including:
- Tagging messages as spam or ham (non-spam) for spam detection.
- Elucidating text meaning and word relationships for machine translation.
- Classifying documents.
- Crafting conversations for chatbots.
- Extracting consumer feelings and opinions from reviews for sentiment analysis.